
HSS Digital
Métopes
Scientific direction
Dominique Roux, directeur de l’IR Métopes
Partners
MRSH
CNRS – InSHS
Université Caen Normandie
Certic
CNRS – InSHS
Université Caen Normandie
Certic
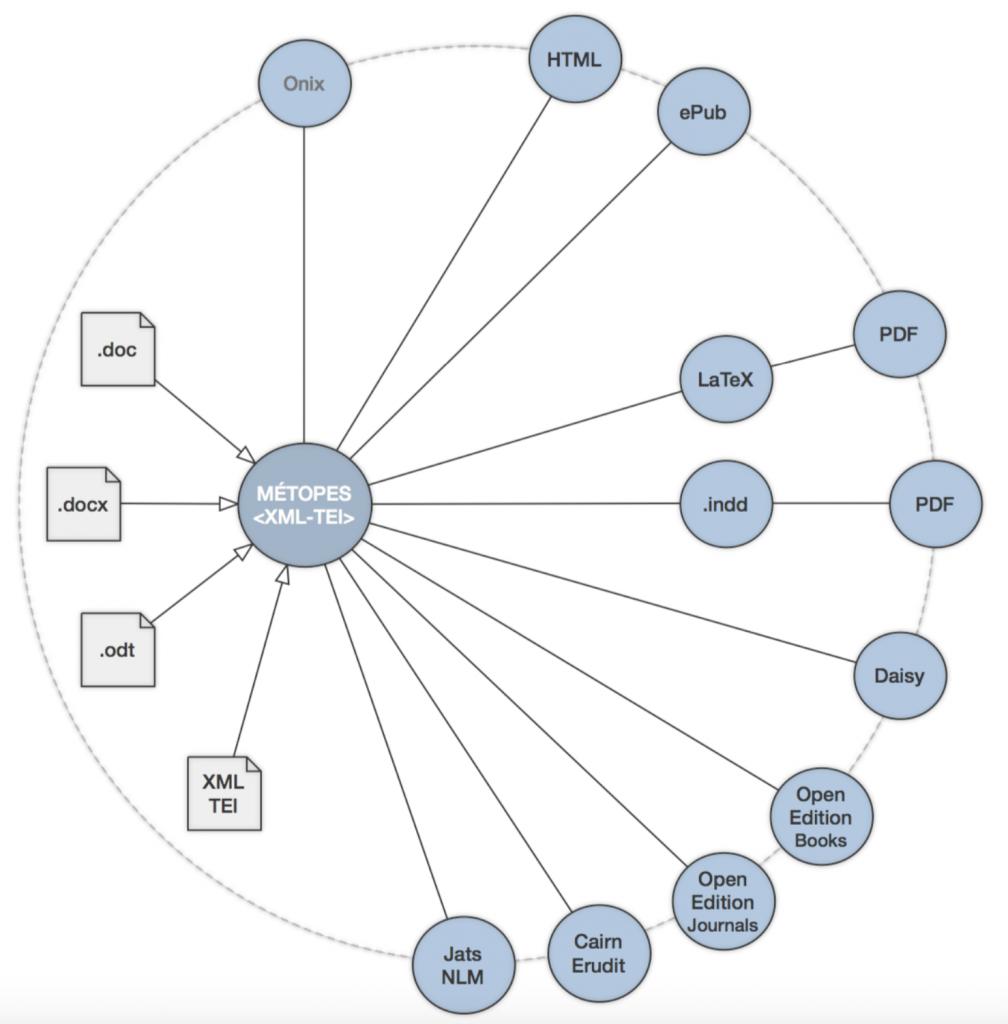
The MÉTOPES project, “Methods and Tools for Structured Publishing ” [1] aims to develop, refine, and freely distribute to the public, through training initiatives for public publishers and CNRS-approved journals, a set of tools and methods enabling them to organize their print and digital production and distribution in a standardized environment with high interoperability potential, based on the Single Source Publishing model [2]. One of the main contributions is to streamline and factorize editorial work within the community of public academic and research publishers, while promoting the implementation of multi-media dissemination strategies, ensuring the sustainability of content and the high quality of associated metadata.
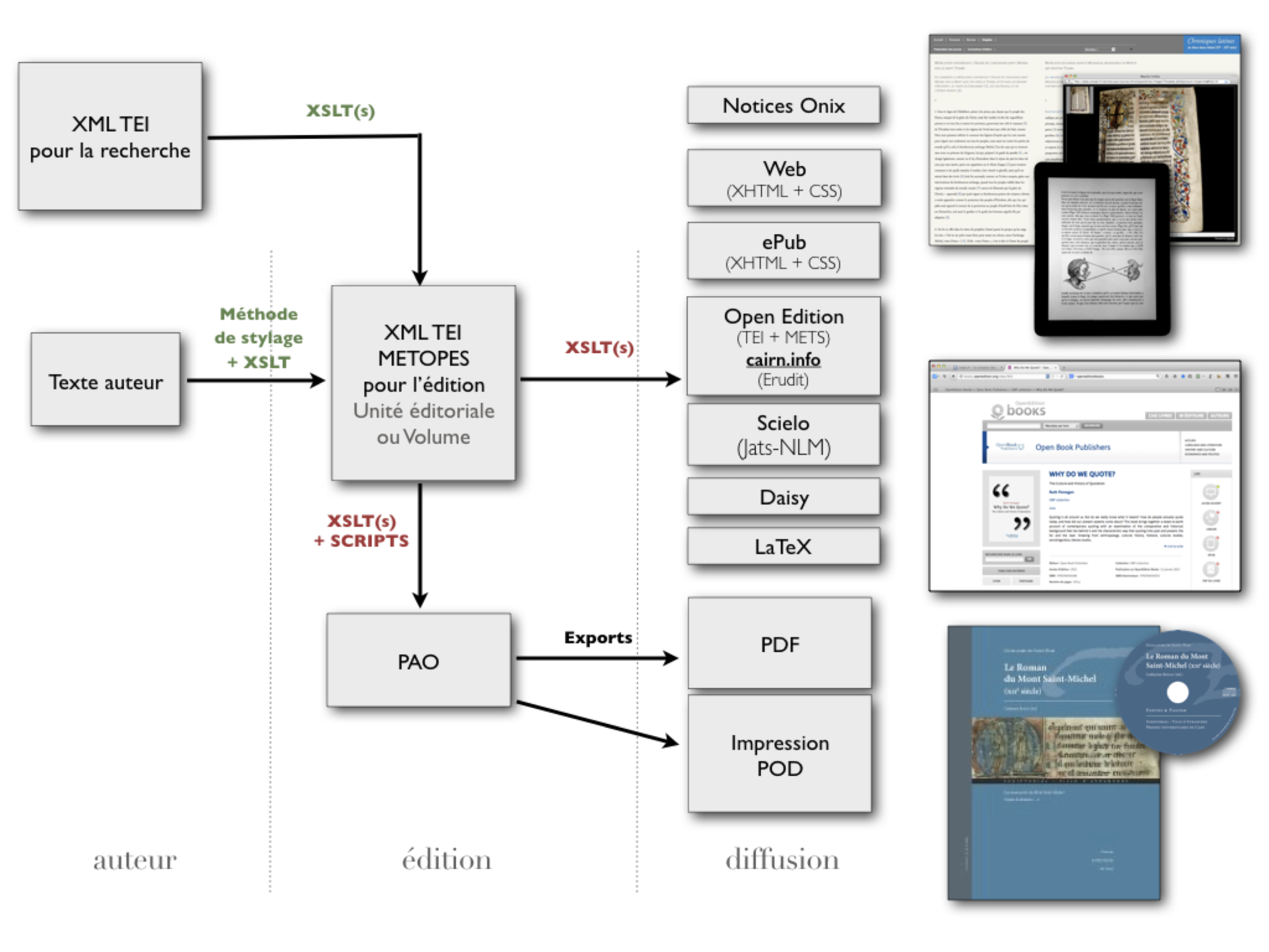
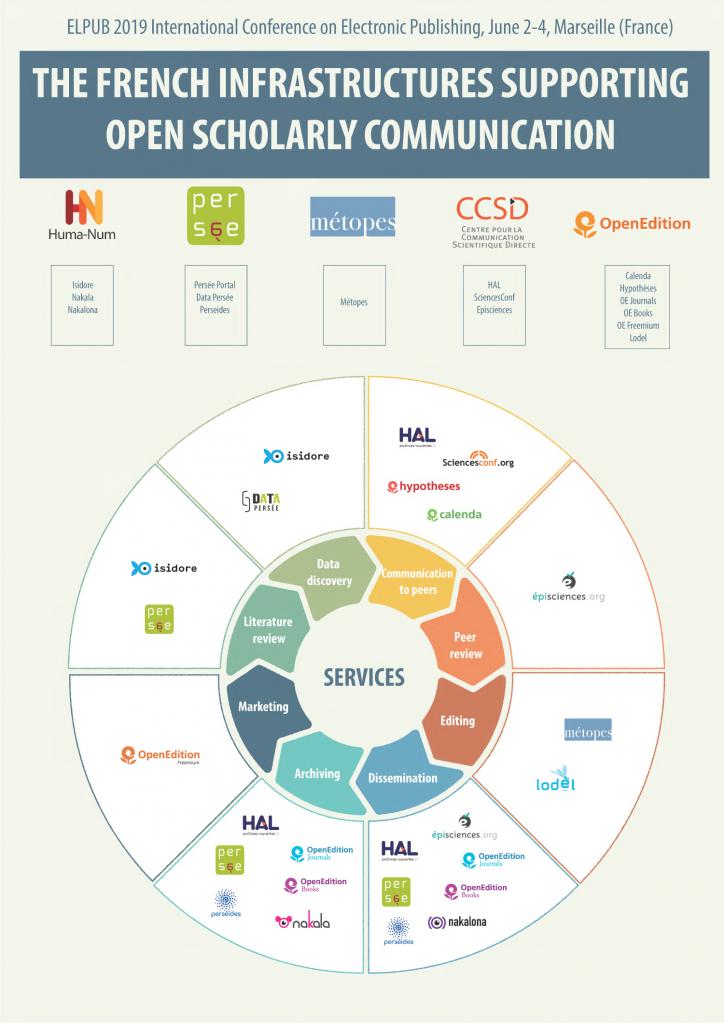
This project, which is mainly focused on content production, is closely linked to the work and developments carried out in parallel by OpenEdition (USR 2004 of the CNRS, Marseille) through its use of the ONIX standard and its applications. Together, these two systems enable the joint development of a repository of standardized content (XML–TEI) with high editorial added value (evaluated, edited, structured, etc.) and a cataloguing and display (dissemination) system that opens up the possibility of deploying a common catalog (ONIX) for associated public publishers (metadata and content). After forming the research and development part of the NUMEDIF [3] national research infrastructure, in 2018 the project became a fully-fledged research infrastructure (University of Caen Normandy – CNRS) under the name IR METOPES. It works in synergy with the three other national infrastructures dedicated to IST: OpenEdition, Collex-Persée, and HAL.
Since September 2013, the same data model [4] has governed OpenEdition’s publications—books and periodicals—and users of the chain, with direct positive consequences for the economics of content distribution. One of these consequences, and not the least, is the elimination of file conversion costs for distribution on platforms [5], but above all, ensuring that the publisher retains full ownership of structured files. These files, the result of unique editorial work, are durable, reconfigurable, guarantee the content, and support multiple forms of distribution. They fulfill all the conditions for fund interoperability, i.e., the possibility of developing a common catalog and implementing a reservoir of publications that “qui chuchotent entre elles” [6]. They thus lay the foundations for networked publishing, mirroring a form of scholarship that is also conceived and constructed in networks today.
This model and the accompanying editorial IT tools make it possible to produce all forms of dissemination from a single source and are already compatible with the formats required for journals on OpenEdition Journals, Cairn.info and for books published on OpenEdition Books.


This technical and organizational model strongly resonates with the realities, demands, and constraints of today’s digital production and distribution environment. Indeed, in terms of interoperability and the economics of knowledge dissemination:
• it is based on norms or standards shared by many players in the field, which is a factor in content interoperability;
• it helps to clarify the concept of “editorial added value” by making it possible to identify and locate it precisely;
• it is a factor in savings, if only because a single editorial intervention allows for a multiplicity of forms of distribution;
• It is independent of economic models: publishers have complete freedom to choose between free and paid distribution models and can build complementarities between forms of distribution.
• It offers new perspectives in terms of rights, based on clarification of the status of the text and clear identification of those responsible for editorial added value. It allows the author-institutional publisher partnership to have, in compliance with copyright, a rich structure from which simplified forms can be produced for distribution purposes only. These aspects can enable the most relevant adaptations to be made in a context where the obligation to distribute in Open Access may (or will) apply;
• it is also a point of convergence in terms of coordination with other professions involved in the “life” of the digital flow (librarians, archivists, researcher-authors, researcher-readers, etc.) and, even more so, in terms of openness to research data (annotated texts and editions from corpora, online theses, etc.);
• it guarantees a certain durability of data. Indeed, the use of Unicode and the documented standardization of structures (XML–TEI) makes the files produced suitable for archiving by the National Computer Center for Higher Education (CiNEs).
Editorial implications and challenges
The importance of standards and the adoption of common or at least interoperable standards is crucial here. Broadly speaking, this involves Unicode for character encoding, XML for describing structures, and the choice of >TEI (Text Encoding Initiative) for semantics [7]. The late 1990s saw the emergence of norms and standards designed to promote a certain stability in digital production and enable interoperability: stabilization of character encoding with the Unicode standard, which makes it possible to exchange texts on a large scale; stabilization of content architecture representation modes with, in parallel with the expansion of the Web, the ubiquity of XML and associated techniques, XSL and CSS; stabilization or rather definition of vocabularies shared by communities and concerning either content (TEI) or products, their cataloging (referencing) and their distribution(s) (Dublin Core, ONIX) .
This set of developments makes it possible to generalize the principle of dissociating content from form and, further still, forms, since one of the challenges is indeed the prospect of multi-media, or even multimodal, publishing.
The challenge underlying the implementation of this model and these techniques cannot be reduced to a set of IT systems or new working protocols alone. It is a question of moving from tool-centric digital publishing to data-centric digital publishing, with the aim of building—both politically and materially—and preserving collections that are part of a digital technical landscape that is no longer imposed but controlled and subject to public editorial policies.
Deployment, training
With the support of AEDRES initially, then, since 2013, with BSN, covering all development and training costs, more than 100 public university and research publishing structures (university presses, journal publishing secretariats, presses of French schools abroad, IFRE presses, etc.) and more than 500 people (editorial managers, publishing secretaries, editors, layout artists, graphic designers, etc.) have been trained in structured publishing methods by staff from the Presses universitaires de Caen et du the Digital Document Center. Each three-day training course is conducted on site and tailored to the editorial concerns of the staff involved. It is organized around the free provision and installation of tools in the department. These on-site training courses are combined with thematic workshops organized within the framework of networks: MEDICI (training for journal editorial secretaries, training for trainers-referents in XML–TEI structured editing tools), Corpus Consortia (MASA, CAHIER), Repères, ANF, AEUP (Operas), etc.
User monitoring and technical support are provided by two CNRS research engineers from the Digital Document Center in conjunction with OpenEdition.
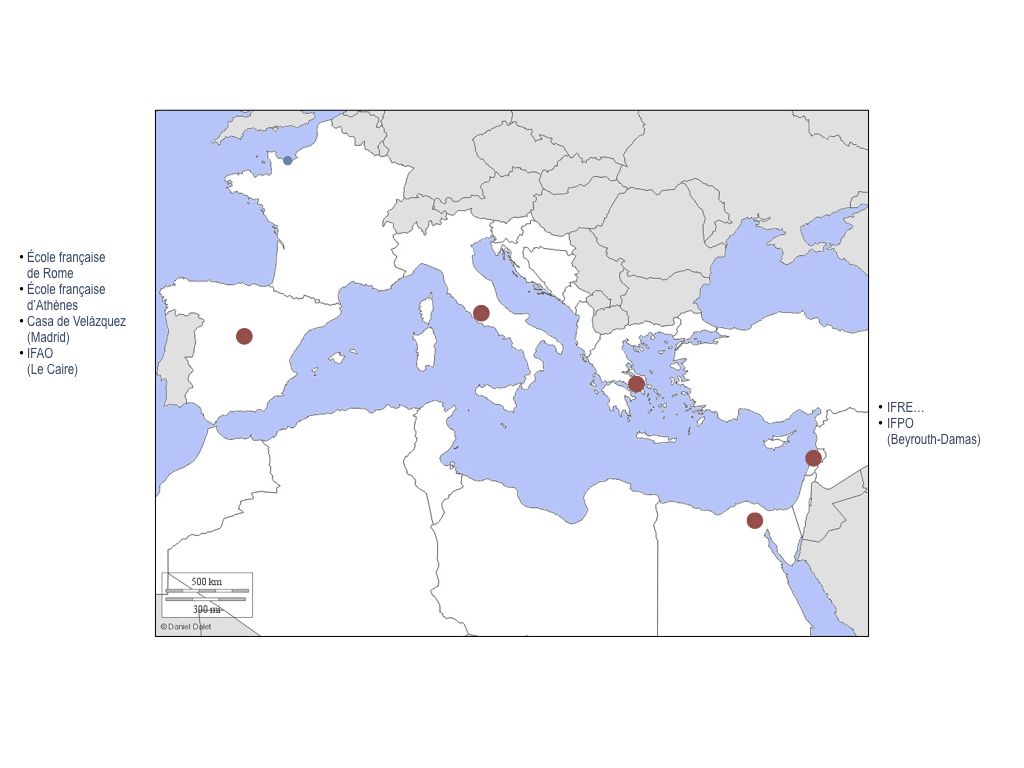
The channel is also distributed abroad under agreements between AEDRES and its correspondents: REUN (Argentina), ASEUC (Colombia), LusOpenEdition (Portugal), AEUP (Association of European University Presses), etc.
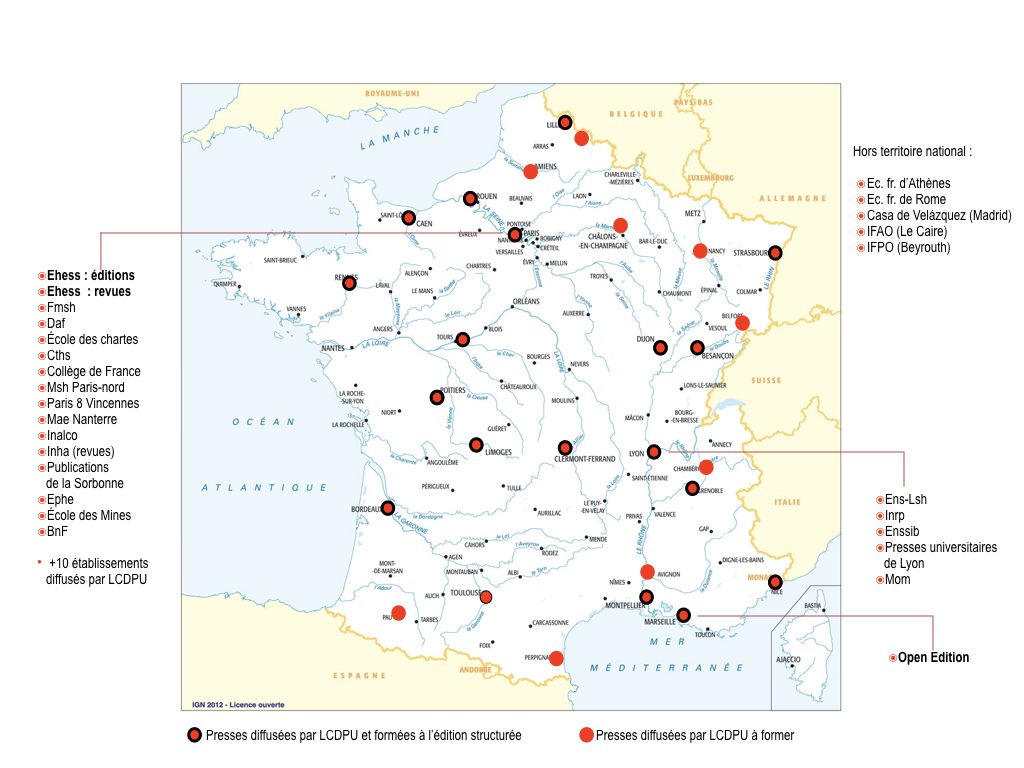
Since 2015, the use of XML–TEI structured editing tools and methods has been recommended by the INSHS for the production and distribution of journals.
[1] Supported by BSN, led by the Digital Document Center under the direction of Pierre-Yves Buard, and by the Caen University Press, with its extensive experience in publishing complex sources, in collaboration with AEDRES. On the models, principles, and methods implemented and their impact on scholarly publishing, see: Pierre-Yves Buard, “Modélisation des sources anciennes et édition numérique” (Modeling ancient sources and digital publishing), Doctoral thesis, University of Caen Basse-Normandie, 2015 (typescript). On the landscape of institutional scientific publishing and the impact of digital technology, see: “L’édition scientifique institutionnelle en France. État des lieux, matière à réflexions, recommandations” (Institutional scientific publishing in France. Current situation, food for thought, recommendations), report (typescript) prepared for AEDRES by Jean-Michel Henny in collaboration with Denise Pierrot and Dominique Roux (submitted to the MENSR in 2015).
[2] This refers to the implementation of the model defined by Robert Darnton, “The New Age of the Book,” Le Débat, 105, 1999, pp. 176-184.
[3] For a presentation of NUMEDIF, see Dominique Roux, “Numédif: au service de l’édition numérique” (Numédif: serving digital publishing), Arabesques, 84, February-March 2017, p. 14.
[4] That is, the use of the same granularity of description for textual elements and editorial forms using TEI vocabulary.
[5] And for all (re)formatting in flux: XHTML, Revues.org, OpenEdition Books, Cairn (model derived from Érudit), ePub 2 and 3… or in page format: InDesign, PDF and soon LATEX, JATS… among others.
[6] To borrow an expression used by Marin Dacos (Blogo Numericus, “C’est le chuchotement des livres qui se parlent…” [It is the whispering of books talking to each other…], 10/22/2008;http://bn.hypotheses.org/167).
[7] Lou Burnard, What is the Text Encoding Initiative?, Marseille, OpenEdition Press (Encyclopédie numérique), 2014 (http://books.openedition.org/oep/1237).